本文共 6954 字,大约阅读时间需要 23 分钟。
如果你曾在企业开发方面具有一些经验,那么基本上可以断言,你必定承担过一些类似于搬运工的职责,将数据从你的数据库中不断地搬进搬出。此外,如果你在这方面有过过往的经验,那么你肯定也曾经做过将大量对共享文件进行解析,并且加载到某个schema的表中的事。从纯文本文件到结构化的XML文件,再到更为艰涩的文件格式(例如ISO 2709),开发者与管理员在这些文件之间不断转换,并从中获取数据,这种状态已经维持了数十年。
\\对于抽取数据文件这种历史悠久的做法,有人提倡也有人批评。批评者们认为,数据文件不是来自于实时的信息源,并且根据所选择的信息格式的不同,要正确地处理这些文件可能需要经过大量的协调与策略。另一方面,提倡者分辩道,数据文件的使用已经有几十年的历史了,而它的结果是产生了丰富的类库与命令,即使是未经过训练的初学者也能够掌握它们的使用方法。
\\这些已经证实了它们实用性的工具让数据文件的解析与加载工作看起来只是举手之劳,对于加载海量数据来说,这些工具通常也是最快的方式。那些数据文件的支持者也会指出,虽然文件并非实时的,但它们提供了数据快照的一个记录集,可以将这些结果进行存档,可用于今后审记员在检查公司的行为是否合法时的有力证明。比方说,在美国法律中,塞班斯法案(Sarbannes-Oxley Act)规定公司必须保留最近至少五年以上1的相关数据。如果你当前的系统是根据这些需求规格处理文件的,那么你的数据流大概会像以下方式一样:
\\(点击放大图像)
\ \\\但是,虽然关于使用数据文件的争议还在继续,但当今世界对于实时信息的渴望却一天比一天强烈,而通过API的方式进行数据检索的这种实践越来越多地开始满足人们的这种渴望。在今后的许多年中,遗留程序与系统仍将从文件中获取数据,但这些系统最终很可能会因为干系人对实时数据的渴望而被取代。当然,为了让这种转变成功地实现,我们还需要新的系统与程序。此外,由于这种方式不会再将数据进行压缩并归档至某个目标文件夹,因此我们必须创建一种自己的数据保留方案。
\\但一般来说,我们希望能够使用一种与从文件中获取数据的解决方案类似的工作流:
\\(点击放大图像)
\ \\解决这一问题的方法有许多种,可以选择一种临时方案并快速地实现它。不过,如果你曾经阅读过我之前所写的文章2,你就知道我很喜欢使用一种更为系统化的方式处理这些问题。实际上,我们在这种情况下可以使用元数据驱动设计以创建一种健壮的架构,它能够承担并执行这些我们所期望的职责。那么,到底元数据驱动设计是什么呢?为了简洁起见,可以将它简单地归结为一种软件设计与实现的途径,让元数据组成并集成这两个开发阶段。换句话说,在这种方式下,开发者能够在整个软件开发的生命周期3中采取敏捷式的迭代。通过使用由领域驱动设计所派生的元数据,你可以进而进行下一步的元数据驱动设计,并且创建出令人印象深刻的灵活架构。
\\正如Mike Amundsen所建议的一样,API的创建应该贯穿整个设计4之中,在我们创建会调用这些API的系统时,也应该保持相同的心态。因此,为了让具有高度复杂性的问题更易于解决,将这种难题分解为各个组成部分是一种良好的实践(由于这种方式有助于使用简洁的方案分别解决整体性问题中的每个部分,因此元数据驱动设计天然的模块化特性对这种情况来说尤其合适)。举例来说,由于API数据检索方式通常会对某个请求所返回的数据的最大数量加以限制,因此我们需要设计一种自己的引擎,并且假设它会通过对该API的循环调用,在大量的数据集中进行枚举。但是,在我们开始处理这些小问题之前,我们需要提前预料到更高级别的问题,也就是在API数据检索中存在着不同的风格。某些提供商在获取本身数据时所采用的机制不够强大,能够参与查询的参数数量有限,甚至完全没有。用户不得不在每次查询中获取完整的内容,并自行处理。某些用户或许希望能够用重复调用的方法获取某个提供商的完整记录,但有很多用户(比如我自己)希望能够获取一部分数据子集,尤其是自最后一次数据获取以来发生过变更的记录(即增量记录)。在更加直接的实现中,提供商或许只需要在URL查询字符串中加入一个参数,就可以获得增量数据。但在更抽象的用例中,审计信息与实际数据是通过两种相互分享的API中获取的。因此,审计API会被首先调用,在结果中提供了一份清单,其中详细地说明了哪些记录与字段在某个日期之后产生了变更。随后可以使用这份清单通过数据API获取增量数据。在我们设计这套架构时,必须考虑到这种方案。
\\尽管我们可以对同时使用某个数据API与对应的审计API的方式进行一些调整,但我们要关注的是在通用的情况下如何系统地对API进行调用。在这两种情况下,我们都需要考虑到某些因素:生成适当的URL、对格式(JSON、XML等等)进行解析,获取特定属性的值、过滤掉不需要的记录等等。为了为这套架构创建一组合适的元数据,最终的结果需要包括一套大范围的数值,这些值能够满足每一个必要步骤的需求,无论是调用审计API或是数据API。为了展现这一点,以下分别显示了一个增量清单以及对应的增量数据:
\\(点击放大图像)
\ \\将记录包装在一个集合体(即\u0026lt;products\u0026gt;)内,并将每条记录作为一个独立的内容体(即\u0026lt;product\u0026gt;)进行保存是一种常见的做法,尽管这一点并不总是成立。API也能够帮助我们处理对大数据集进行重复式调用的问题(即分页),其做法是提供一个对下一批数据(即\u0026lt;hasMore\u0026gt;与\u0026lt;next\u0026gt;)的链接,这种做法也十分普遍。这些模式能够帮助我们在自己的引擎中打造泛用性的功能。为了在这些记录中进行枚举,我们可以利用运行时环境中提供的底层机制来实现这一点。在本文的余下部分中,我们将专注于.NET作为我们所选定的平台。在这个案例中,.NET XPath库与W3C XPath符号5为我们提供了在这些记录间进行移动的必需功能。
\\在我们提供一种用以实现这套数据获取引擎的元数据之前,由于我们目前在讨论的是原始的数据,因此我们应当趁此机会解决在法律方面的关注点。为了满足对系统进行审计的人员的需求,我们应当将这些原始的数据持久化,以证实我们现有数据的真实性。我们接下来要创建一张表,它描述了我们的特定目标,此外还有一张表记录了对我们的查询所返回的API响应:
\\(点击放大图像)
\ \这些数据不仅满足了我们对于数据保留政策的需求,同时我们也有了一个潜在的健全性检查工具,可以作为我们的数据处理管道中的第一个步骤。如果在之后的步骤中对于这个引擎的性能有任何疑问,我们都可以随时检查这个响应的“快照”,以确保我们正确地解析并加载了包含在响应中的值。
\\现在我们就具有了一个适当的基准线,我们终于可以设计这个元数据了,它将用于对如何从指定的API中获取数据进行配置。为了正确地执行以上描述的这个假想的流程,流程的第一步就是通过审计API获取变更清单。有了这份变更清单之后,我们就可以获取之前所描述的增量记录了,可以选择单独获取或批量获取:
\\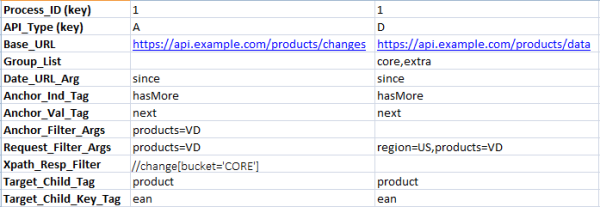
这个schema的原型与示例的行数据将成为我们为引擎进行元数据驱动设计的第一步。它将试图捕捉能够驱动我们的软件的抽象概念(正如领域驱动设计之父所说:“只有找到一组适用于所有细节的抽象概念后,工作才算成功6”)在这个示例中,类型’A’这一行表示获取变更清单所必须的API配置信息,而其它所有行中的值组成了我们用于进行实际数据检索所需的配置。之前,我曾提到需要某种能力,通过重复式的调用获取大数据集的内容。(尽管在XML中的内容所包含的数据集仅包含了一个增量数据,但在大多数情况下所指向的记录集会大上许多)。我们已经有了对该URL进行第一次调用所需的元数据了,并且’Anchor’列能够帮助我们在一个大集合中进行枚举,以实现这些重复式的调用:
\\最初的Auditing API调用
\\http[s]://api.example.com/products/changes?since=1432746033000\u0026amp;products=VD
\\之后的Auditing API调用
\\http[s]://api.example.com/products/changes?limit=1000\u0026amp;anchor=MTQyNDcyN
\\这些元数据不仅提供了用于生成URL的构建块,我们现在还拥有了对API调用的响应内容进行解析与过滤的功能。作为一个小提示,我会建议你实现某个接口(例如IEnumerable),它会无缝地对响应内容中的数据进行枚举,并且将之后的API调用也作为整个枚举过程中的一部分。由于.NET平台在这个示例中是我们的底层运行环境,因此这里.NET XPath类库就派上了用场。通过使用XPath符号查询某个元数据列(例如“Target_Child_Tag”和 “Target_Child_Key_Tag”)中的数据,我们就能够在响应体中的记录之间方便地跳转,并获取我们将进行处理的数据体。只需几行代码,就能够使用.NET LINQ功能获取数据,并忽略响应体中我们并不感兴趣的那部分数据:
\\List\u0026lt;Hashtable\u0026gt; CurrRecordList =\ (\ from tmp in CurrXmlResponse.Root.Elements(TargetChildTag)\ where tmp.XPathSelectElement(XPathRespFilter) != null\ \u0026amp;\u0026amp; tmp.XPathSelectElement(XPathRespFilter).Value != null\ select new Hashtable()\ {\ { targetChildKeyTag, tmp.Element(targetChildTag).Value }, \ { “body”, tmp.ToString() }\ }\ ).ToList();\\ 这个泛型功能允许我们将某个响应体中的记录加载到某个容器之中。在审计API的情况下,这段LINQ代码的执行结果会生成一个列表,其中包括了我们的增量清单中的各个部分。而在数据API的情况下,这个结果列表将包含实际产品记录的内容。这个变更清单容器的目的在于:它能够作为一份指南,告诉我们应当通过数据API获取哪些部分的产品记录。不过,在数据记录列表的情况下,我们还需要更多的说明。我们将如何处理这些数据?我们如何打造一套将这些数据持久化的机制?当然,我们需要进一步地实现元数据驱动设计!
\\在这个架构游戏中的倒数第二条功能就是将这些增量记录指向它们最终的目的地。虽然我们可以选择将这些增量记录持久化到文件系统(与变更清单一起)中,大多数企业系统都将数据库选为他们的主要存储机制,这一点应当不会令你感到吃惊。如果你只是需要显示这些数据,那么你可以选择使用一种NoSQL数据库,例如MongoDB以保存这些增量记录(甚至选择保存完整的原始响应数据),但由于查询以及处理这些常见的需求,多数企业数据系统都会选择将这些属性分散保存在关系型数据库中的多张表中。在这种情况下,我们需要创建一系列元数据,它们将帮助我们将增量记录转移到某个适当的预发布区域:
\\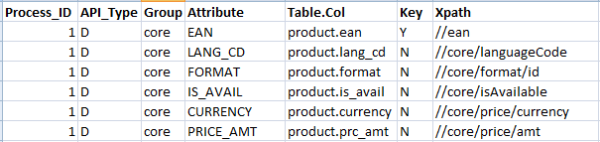
如果这套引擎的软件实现足够良好,我们还可以创建一个智能的审计子系统,它能够了解当数据进行这个预发布区域时,将如何检测变更并进行记录。最重要的是,如果需要在记录中加入额外的数据并进行持久化,只需方便地添加更多的行就可以了,这些改动对代码产生的修改要求减至了最低,甚至完全为零。
\\最后,我们还需要实现对这些响应记录的归档操作。根据你的数据库配置以及所预期的变更数量,可以合理地选择暂时将这些记录保留在响应体相应的表中,考虑到法律与所有权政策的迫切需求。不过,这些数据很有可能超出你的数据库的空间限制,并且在相关人员进行查询时会表现得很慢。在这种情况下,可以考虑其它几种选择。一种选择是与一位DBA进行合作,共同创建一个对你的响应体表中的某些部分进行归档的策略。不过,在这种情况下,这个解决方案将不再属于你的引擎的领域之内,同时也将脱离你的掌握范围之外。对于不喜欢这种方式的其他人来说,还有一种替代方案。在过去几年中,许多提供商都以合理的价格推出了数据归档服务(例如Microsoft Azure Backup)。虽然其中有些服务要求你安装客户端的软件,但这种选择能够为你提供除了对数据进行简单地归档之外的服务(例如数据恢复等等)。当然,这套API数据检查引擎需要配合你的归档解决方案。在使用某些服务的情况下,该引擎或许要将原始的响应体搬到某个文件系统中,通过它自动分发到远程的地点。不过,只需要几行元数据与几行代码,你就能够充分利用这一服务,在你的引擎工作流中创建一种灵活的归档步骤。
\\不过,在我们开始感觉飘飘然之前,你或许该考虑到这种设计中缺乏了任何形式的保护机制。比方说,我们目前假设这套系统能够以某种方式运行,也就是说这个API服务器能够提供指向一些增量记录的变更清单。但是,如果今后这些变更的数量产生了变化,使我们目前的期望突然间变得与事实不符了呢?如果突然间产生了潮水般的变更数量,压垮了我们的系统呢?又如果这个API服务器突然间无法正常运行,开始了无限循环,不断地发送给我们相同的变更清单呢?在最后一种情况中,我们在潜在中也可能会无意间对API服务器造成了一种DoS攻击,而如果最终发现这个无意中产生的攻击是来自于你的引擎本身,情况会变得更加严峻。这会令人感觉尴尬(至少可以这么说),我们应该致力于避免这种情形,无论是出于技术原因还是政治上的原因。那么为了避免这种情形出现,我们需要做些什么呢?我们将再一次创建一个健壮的元数据驱动解决方案,以帮助我们对应这些潜在的问题:
\\
当然,像“Email”与“打开阀门”这样的操作需要在你的引擎中实现,不过实现这些功能应当十分简单。由于我们已经了解了领域模型,我们已有了足够的业务知识,因而可以建立一些对问题场景进行量化的参数值,由此触发应对这些问题的适当的回应。更重要的是,我们还可以简单地对这些数值进行调整,以适应不断变化的需求,因为随着时间的推移,你的环境以及期望很可能会产生改变。
\\有了这套模型之后,我们就能够实现一套架构,它对于已建立的IT部门来说是一种能够令人心安的转变。同时由于我们为通过API检索到的数据保留了记录快照,我们就能够满足管理者在法律问题以及心理上的需求。此外,一如既往,我们能够在过程中采用敏捷,以进一步改善这个数据检索引擎。如果你倾向于使用数据API(而不会产生一个相应的调用去获取变更清单),那么你完全可以选择移除整个设计中关于变更清单的这一部分的功能,以及对应的代码。如果你还希望加入某种策略,使旧记录能够被自动移除,你也可以对设计进行迭代,加入另一个元数据集(以及对应的代码)。这个新功能能够基于某些数值,例如源标识以及已保存记录所允许存在的最长时间,将无效的记录移除。无论在哪一种情况下,这种配置都能够为数据检查未来的需求提供一种灵活的设计。
\\关于作者
\\Aaron Kendall是一位居住在纽约的软件工程师,在企业数据系统的设计与实现方面具有近20年的经验。他刚开始是一位设备驱动程序的开发者,随后转为专业软件的开发者,在此过程中他表现出了对软件设计及架构方面的热情。他曾经在多个平台上通过多种语言创建了具有创新性的商业解决方案,以及许多作为自由职业者创建的软件项目,包括开源的软件包,以及游戏设计和移动应用。如果你想进一步了解他的工作,欢迎阅读他在上的帐号以及他的。
\\参考
\\- 美国证券交易委员会(2003年1月27日)(Final Rule: Retention of Records Relevant to Audits and Reviews)17 CFR Part 210, RIN 3235-AI74\\
- Kendall, Aaron (2015年1月19日) \\
- Kendall, Aaron (2014年12月2日) MetaDataDojo\\
- Amundsen, Mike (2014年12月7日)\\
- W3C (2008年9月) RFC 5261\\
- Evans, Eric (2003年8月30日)领域驱动设计:软件核心复杂性应对之道Addison-Wesley Professional\
查看英文原文:
转载地址:http://gvutx.baihongyu.com/